
Learn what normalization is in NLP, machine learning, and data science. Explore techniques like min-max scaling, z-score, text normalization, and their real-world applications.
Ever wonder why your model just won’t behave no matter what you do? Yeah… nine times out of ten, it’s normalization—or, well, the lack of it.
Introduction – What Is Normalization and Why It Matters
Okay, let’s be honest. Raw data is a mess. And I mean really messy. I remember staring at my first dataset — customer reviews, ratings, all kinds of numbers and text — and just blinking at the screen. Emojis, typos, missing values… seriously, someone could have planted a random cat GIF in there and I wouldn’t have been surprised.
Normalization is basically tidying up your data. Making it fair, comparable, and friendly for machines. Think of it like prepping ingredients before cooking. You wouldn’t just toss random, uncut veggies into a pan and hope for a five-star meal, right? Same thing here.
Imagine this: you’re predicting house prices with these features:
- Area: 500–5000 sq ft
- Bedrooms: 1–5
- Distance to city center: 0–20 km
Without normalization, “Area” will dominate. It’s huge. The other features? They barely get a say. Normalization levels the playing field.
In NLP, it’s a bit similar. “I’m LOVING this!!!” and “i am loving this” might mean the same thing to us, but the computer sees them as totally different. Normalization helps the machine “get it” too.
Normalization = consistency + comparability + smarter models
Skip it, and… well, I’ve seen models go completely haywire. Not fun. Trust me on that.
Discover how Normalization transforms NLP, Machine Learning, and Data Science — ensuring cleaner, smarter, and more reliable models.
Explore more AI insights on Craze Neurons:
🔗 AI in Cricket | Future of Data Analytics 2025 | Why Learn Data Science & AI | AI Interview Questions | Automation Trends & Future | Data Visualization Tools | Generative & Agentic AI | ATS-Friendly Resume Guide | AI Everywhere in India | AI Business Automation Future | Python Applications 2025 | SWOT Analysis Guide | Web Scraping with Python
Normalization in NLP (Natural Language Processing)
Text is messy. Humans? We handle nuance effortlessly. Computers? Nope.
Take these:
- “I’m happy.”
- “im HAPPY!!!”
- “sooo happyyy :)”
Same sentiment. Humans get it instantly. Machines? Not without normalization.
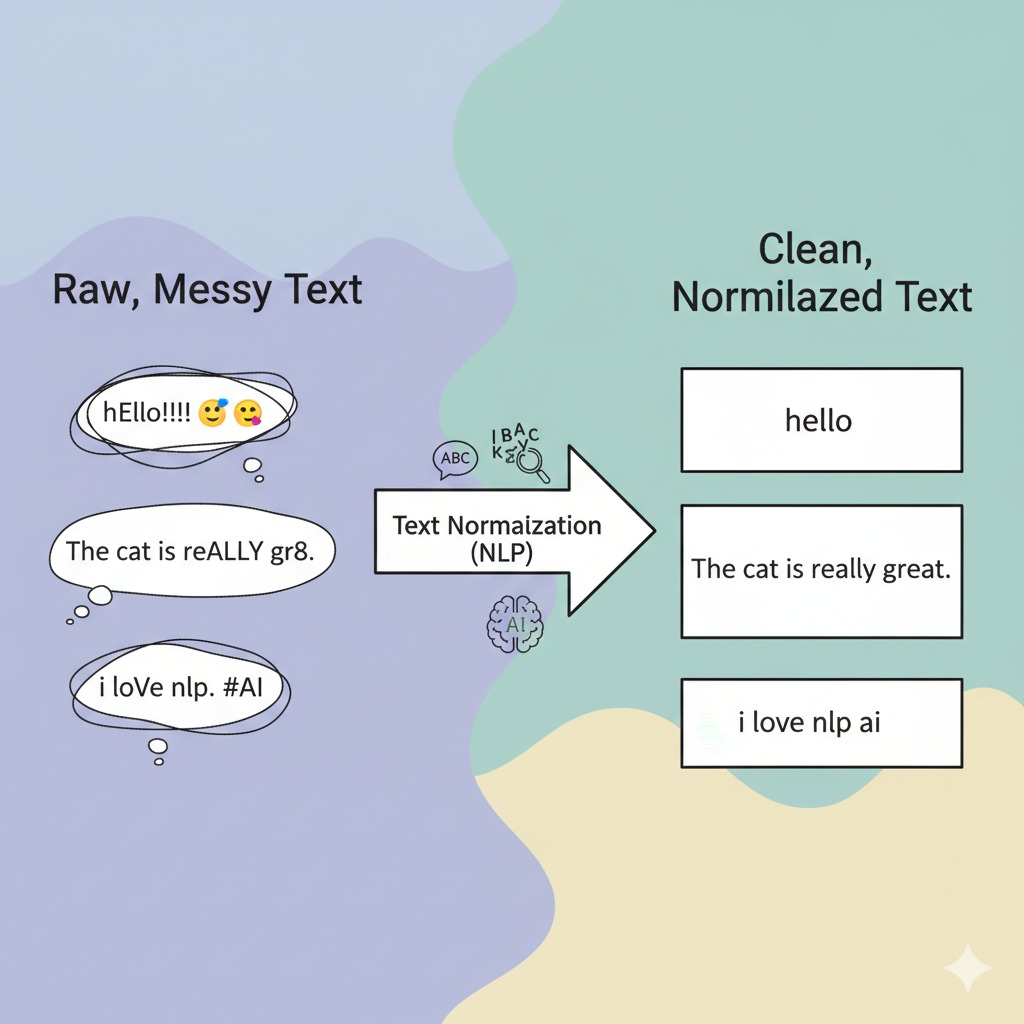
1. Lowercasing
Easiest step ever. Just turn everything lowercase. “Apple” = “apple”. Done.
Example:
Before: “NLP is FUN and POWERFUL!”
After: “nlp is fun and powerful!”
Pretty safe — unless you’re doing Named Entity Recognition. I once ignored this, and the model thought “US” and “us” were the same. Spoiler alert: it was not.
2. Removing Punctuation and Special Characters
Punctuation is mostly noise. But wait — in sentiment analysis, punctuation can carry emotion.
Example:
Before: “Wait… what?! This is crazy!!”
After: “Wait what This is crazy”
Fun story: I over-cleaned a social media dataset once. Flattened the emotions completely. The model basically said “meh” to everything. Lesson learned: context matters.
3. Removing Stopwords
Stopwords like the, is, and, in are everywhere but often meaningless.
Example:
Before: “The cat is on the mat.”
After: “cat mat”
I usually remove them in classification tasks — reduces noise, makes life easier for the model.
4. Stemming
Stemming chops endings to get a root form. Quick, rough, kinda ugly.
Example:
running → run
runner → runn
Not always a real word. Who cares? Machines don’t.
5. Lemmatization
Smarter than stemming. Uses grammar and vocabulary rules to find proper base words.
Example:
better → good
am → be
running → run
Slower, yes. But accuracy matters for chatbots, translation, or summarization. I usually go lemmatization when precision counts.
6. Handling Contractions and Emojis
Social media is full of “can’t”, “I’m”, 😂, 😭… you get it. Expanding contractions and emojis keeps meaning intact.
Example:
I’m 😂 → I am laughing
Skip this, and half your sentiment analysis might just misfire. Been there, done that. Not fun.
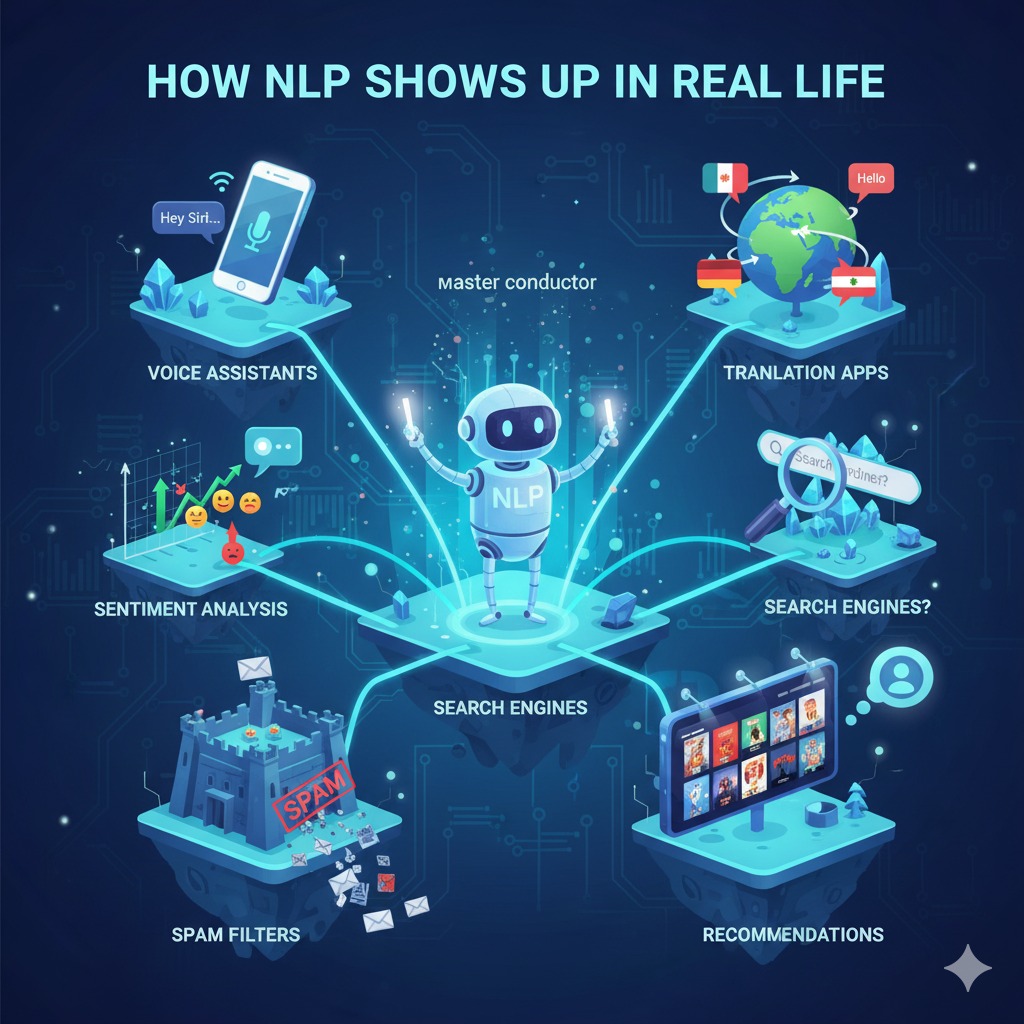
NLP Applications in Real Life
- Chatbots — understand typos and slang
- Search engines — match queries better
- Voice assistants — standardize transcripts
- Sentiment analysis — detect emotions in messy text
Bottom line: normalization is the foundation. Without it, your NLP pipeline is wobbly at best.
Normalization in Machine Learning & Data Science
Numbers can be messy too. Features like income, age, or area are all over the place. Some models assume comparable ranges — distance-based models (KNN, K-means) and gradient-based models (neural nets, logistic regression) are super sensitive. Skip normalization and things can go sideways fast.
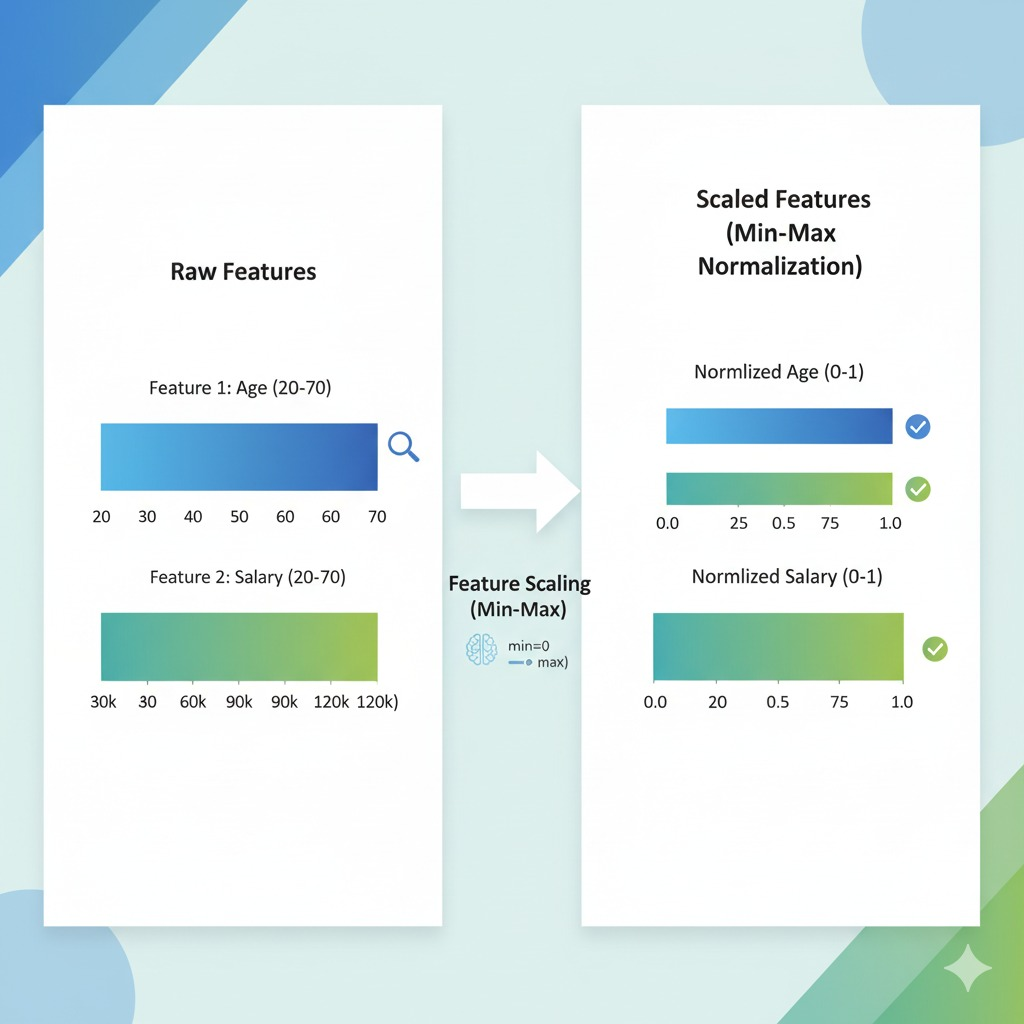
1. Min-Max Scaling
Rescales data to [0,1]. Simple.
Formula:
[
x’ = \frac{x – x_{min}}{x_{max} – x_{min}}
]
Example:
Age 30 in a 20–60 range → 0.25
I love this for bounded features like pixels or percentages. Easy and effective.
2. Z-Score Normalization (Standardization)
Centers data around 0, unit variance.
Formula:
[
x’ = \frac{x – \mu}{\sigma}
]
Perfect for roughly normal distributions — heights, weights, exam scores. Works well with SVMs, logistic regression, PCA. Oh, and by the way, always check the distribution first. You’d be surprised.
3. Robust Scaling
Life-saver for outliers. Uses median and IQR instead of mean and SD.
I once had a dataset with crazy outlier incomes. Normal scaling? Disaster. RobustScaler saved the day.
4. Log Normalization
Compress skewed distributions. Big numbers don’t overshadow small ones.
Formula:
[
x’ = \log(1 + x)
]
Finance, population data, transaction counts… this one’s super handy.
5. Unit Vector Normalization
Scales vectors to length 1. Often used in text embeddings or recommendation systems.
I use this when cosine similarity matters — works like magic.
Real-World ML Applications
- Image processing — normalize pixels for CNNs
- Finance — scale stock indicators
- Healthcare — normalize medical readings
- IoT — calibrate sensor data
Tools & Libraries
- NLTK — beginner-friendly text preprocessing
- spaCy — lemmatization, POS tagging, NER
- scikit-learn — MinMax, Standard, Robust scaling
- pandas — quick normalization in DataFrames
- TensorFlow/PyTorch — built-in normalization layers
Best Practices
- Know your data — not all models need scaling.
- Split first, then scale training data only. Avoid leakage!
- Handle outliers carefully — log or robust scaling helps.
- Pick the method based on model type.
- NLP: balance speed vs accuracy (stemming vs lemmatization).
- Automate with pipelines — your future self will thank you.
- Always monitor performance — every dataset is different.
Conclusion
Normalization isn’t flashy. But it’s quietly powerful. NLP? Makes text understandable. ML? Prevents domination by one feature. Skip it, and even a great model can misbehave.
Think of it as tuning an orchestra. Without it, even the best musicians sound off.
15 Quick Q&As
- What is normalization? Making data consistent and comparable.
- Do all models need it? Nope, tree-based models often skip it.
- Normalization vs standardization? Rescale vs center/scale.
- Why normalize in ML? Prevent large features from dominating.
- Text normalization? Clean and standardize text.
- Min-Max vs Z-score? Range vs standardization.
- Skip normalization when? Tree-based models like Random Forests.
- If skipped? Slow training, lower accuracy.
- Outliers? Use log or robust scaling.
- Libraries? NLTK, spaCy, scikit-learn, pandas, PyTorch.
- Same as cleaning? No, cleaning fixes errors; normalization fixes scale.
- Effect on neural networks? Smoother gradients, faster convergence.
- Reduce overfitting? Indirectly, by stabilizing training.
- Before or after split? After — fit only on training data.
- Time-series useful? Yes, especially for LSTM or ARIMA.
✨ Final Thought
Normalization might not look glamorous. But it quietly makes your models efficient, fair, and reliable. Treat it like brushing your teeth — boring, but skipping it? Bad news.
Next Step – Explore Services with Craze Neurons
When we look at the path to growing our skills, career, or business, we find that it is not only about time or effort but about the ways in which we use guidance, tools, and experience. At Craze Neurons, we offer a set of services that can act as a lens into knowledge, performance, and opportunity. Through these offerings, we can see the depth of learning and the perspective that comes from practical engagement.
- Upskilling Training – We provide hands-on training in Data Science, Python, AI, and related fields. This is a way for us to look at learning from both practical and conceptual perspectives.
👉 Click here to know more: https://wa.me/918368195998?text=I%20want%20to%20Upskill%20with%20Craze%20Neurons - ATS-Friendly Resume – Our team can craft resumes that are optimized for Applicant Tracking Systems (ATS), highlighting skills, experiences, and achievements. This service is available at ₹599, providing a tangible way for us to make first impressions count.
👉 Click here to know more: https://wa.me/918368195998?text=I%20want%20an%20ATS-Friendly%20Resume%20from%20Craze%20Neurons - Web Development – We build responsive, SEO-friendly websites that can be a framework for growth. It is a way for us to put ideas into structure, visibility, and functionality.
👉 Click here to know more: https://wa.me/918368195998?text=I%20want%20a%20Website%20from%20Craze%20Neurons - Android Projects – These are real-time projects designed with the latest tech stack, allowing us to learn by doing. Guided mentorship gives us a chance to look at development from a practical lens and to understand the why behind each decision.
👉 Click here to know more: https://wa.me/918368195998?text=I%20want%20an%20Android%20Project%20with%20Guidance - Digital Marketing – We provide campaigns in SEO, social media, content, and email marketing, which can be used to see our brand’s reach and engagement from a deeper perspective.
👉 Click here to know more: https://wa.me/918368195998?text=I%20want%20Digital%20Marketing%20Support - Research Writing – We deliver plagiarism-free thesis, reports, and papers, which can help us explore knowledge, present ideas, and communicate insight with clarity.
👉 Click here to know more: https://wa.me/918368195998?text=I%20want%20Research%20Writing%20Support
In all these services, we can see that learning, building, promoting, or publishing is not just a task but a process of discovery. It is a way for us to understand, measure, and reflect on what is possible when guidance meets effort.
❓ Frequently Asked Questions (FAQs) – Craze Neurons Services
1. What is included in the Upskilling Training?
We provide hands-on training in Data Science, Python, AI, and allied fields. This allows us to work with concepts and projects, see practical applications, and explore the deeper understanding of each topic.
2. How does the ATS-Friendly Resume service work?
Our team crafts ATS-optimized resumes that highlight skills, experience, and achievements. This is a service priced at ₹599 and acts as a lens to make the first impression clear, measurable, and effective.
3. What kind of websites can Craze Neurons build?
We build responsive and SEO-friendly websites for businesses, personal portfolios, and e-commerce platforms. This enables us to translate ideas into structure, visibility, and functional design.
4. What are the Android Projects about?
We offer real-time Android projects with guided mentorship. This gives us an opportunity to learn by doing, understand development from multiple angles, and apply knowledge in a controlled, real-world context.
5. What does Digital Marketing service include?
Our service covers SEO, social media campaigns, content marketing, and email strategy, allowing us to look at brand growth quantitatively and qualitatively, understanding what works and why.
6. What type of Research Writing do you provide?
We provide plagiarism-free academic and professional content, including thesis, reports, and papers. This allows us to express ideas, support arguments, and explore knowledge with depth and precision.
7. How can I get started with Craze Neurons services?
We can begin by clicking the WhatsApp link for the service we are interested in. This lets us communicate directly with the team and explore the steps together.
8. Can I use multiple services together?
Yes, we can combine training, resume, web, Android, digital marketing, and research services. This allows us to see synergies, plan strategically, and use resources effectively.
9. Is the training suitable for beginners?
Absolutely. The courses are designed for learners at all levels. They allow us to progress step by step, integrate projects, and build confidence alongside skills.
10. How long does it take to complete a service or course?
Duration depends on the service. Training programs vary by course length. Projects may take a few weeks, while resume, website, or research work can often be completed within a few days. This helps us plan, manage, and achieve outcomes efficiently.
Stay Connected with Us
🌐 Website: www.crazeneurons.com
📢 Telegram: https://t.me/cenjob
📸 Instagram: https://www.instagram.com/crazeneurons
💼 LinkedIn: https://www.linkedin.com/company/crazeneurons
▶️ YouTube:https://www.youtube.com/@CrazeNeurons
📲 WhatsApp: +91 83681 95998



2 Responses
I used to be very happy to seek out this web-site.I needed to thanks for your time for this glorious read!! I undoubtedly enjoying every little bit of it and I’ve you bookmarked to check out new stuff you weblog post.
It’s laborious to search out knowledgeable people on this topic, but you sound like you realize what you’re speaking about! Thanks