Sentiment analysis can be described as a method where we identify if text carries a positive, negative, or neutral opinion. We often see this applied in product reviews, customer feedback, and online comments, where the issue is not only about classifying words but also about how meaning fits into data-driven tasks. Some of us may ask what value comes from knowing these sentiments, while others may question why the result may not always reflect the full depth of human expression. This tension invites us to think about how to do text analysis in ways that balance accuracy with interpretation. When we design an llm project, the first step is data collection, and here we must think about both scale and quality. A large set of reviews can give measurable outcomes, while a smaller set may let us see context that numbers alone cannot provide. The dilemma arises once more from a technical issue: should we depend on quantitative counts of positive or negative outputs, or should we also allow space for qualitative meaning that cannot be measured? Both approaches have value, and the decision may depend on the case, the time, and the problem at hand.
In practical terms, we can carry out sentiment analysis using gen ai with ready models that are trained on large collections of text. These models are built to classify words, sentences, or even long documents into sentiment categories, and they can do so with speed that manual work cannot match. As we use them, we see how such tools reduce the manual effort, yet we also notice that some outputs may miss cultural or contextual meaning. To make this work in a technical workflow, we can set up a sentiment analysis using python gen ai project. Python libraries, such as transformers, allow us to call pre-trained models that are already adapted for sentiment tasks. We can run them on thousands of lines of data in one go, check accuracy, and then compare if the system output aligns with human review. We may find cases where the system achieves high numerical accuracy, but the interpretation of a phrase may still feel different to a human reader. The issue, then, is not only about technical performance but also about reflection. We ask ourselves what we gain, what we lose, and why this balance matters in applied research. Some of us may accept the efficiency of automated systems, while others may want to keep human review in the process. No single answer is final; it is a continuing question that keeps us engaged in both technical and ethical reasoning.
What are LLMs?
Large Language Models (LLMs) are data-driven systems that are trained on very large sets of text. They use transformer-based architectures where attention layers allow the model to keep track of both short and long dependencies in language. We see that such models can be used in different cases, as they can perform text classification, summarization, translation, sentiment analysis, or question answering. When we look into the output, the model does not only work with individual words but also with patterns across sentences and documents.
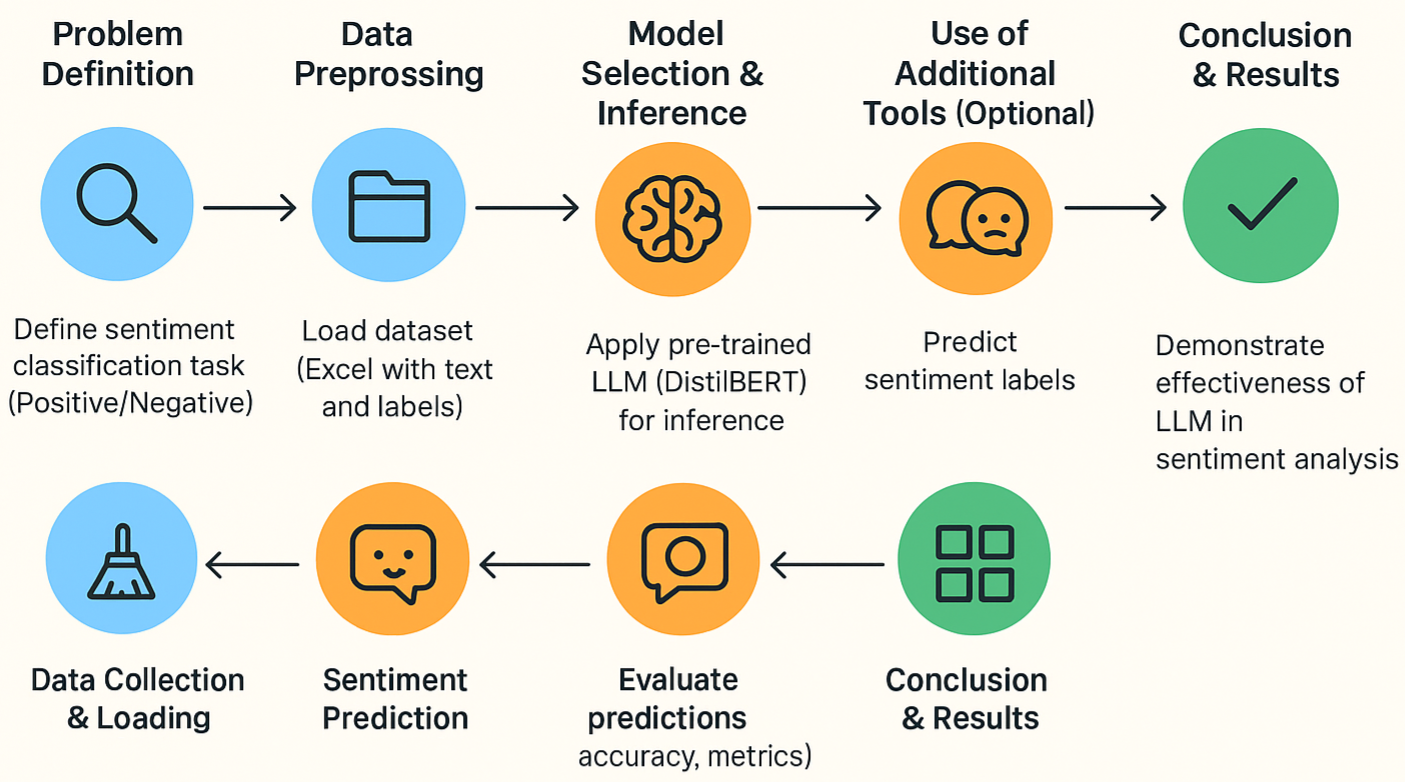
When working on a sentiment analysis project with Large Language Models (LLMs), it’s important to follow a structured pipeline. Each phase plays a key role in building a proper and reliable project. Let’s go step by step:
1. Problem Definition
Every project starts with a clear goal. Here, the task is to classify text into positive or negative sentiment. Defining the problem helps us stay focused and measure success effectively.
2. Data Collection & Loading
A good dataset is the backbone of any machine learning project. In this step, we gather data (for example, an Excel file with text and labels) and load it into our workspace. Without quality data, the project cannot move forward.
3. Data Preprocessing
Usually, data needs cleaning, but in this project, the dataset was already well-structured. Preprocessing ensures that the data is in the right format so the model can understand it better.
4. Model Selection & Inference
Instead of building a model from scratch, we use a pre-trained LLM like DistilBERT. This model has already learned language patterns, so we can directly use it to perform sentiment classification with good accuracy.
5. Sentiment Prediction
Once the model is ready, it predicts whether a given text is positive or negative. This is the main outcome of our project and shows how well the model can understand human emotions in text.
6. Use of Additional Tools (Optional)
Sometimes, we add extra tools like TextBlob or visualization libraries to cross-check results or make them easier to understand. This step helps us strengthen our analysis.
7. Evaluation & Visualization
Here, we check how well the model performed. Metrics like accuracy, precision, recall, and F1-score give us a clear picture of the results. We can also use bar charts or confusion matrices for better visualization.
8. Conclusion & Results
Finally, we summarize the findings and highlight how effective the LLM was in solving the problem. This step also helps identify areas for improvement in future projects.
This structure makes the project easy to follow and helps readers understand how each phase contributes to building a reliable sentiment analysis system using LLMs.
Benefits of Using Pre-trained Models like DistilBERT
When we think of pre-trained models such as DistilBERT, we can see practical benefits that are often clear in real projects.
- Deep Language Representation: The model has been trained on a large corpus, so it can capture details of grammar, word order, and meaning.
- Reduced Training Time: Since the model is already trained, we can use it directly for inference, which lowers both cost and time.
- High Accuracy: In many benchmarks, these models show accuracy levels that are often above 85–90%, which means fewer manual corrections are needed.
- Ease of Use: With libraries like Hugging Face, we can call the model in a few lines of Python code and begin testing without extra steps.
These points help us see why pre-trained systems are often selected for applied projects in text classification or sentiment analysis.
Why Fine-tuning is Sometimes Avoided
Fine-tuning means taking a pre-trained model and training it further on a smaller dataset that is closer to our task. Yet, in many projects, we see that fine-tuning is skipped.
- Resource Constraints: Fine-tuning may require hours of GPU use, which can be expensive for small teams.
- Simplicity and Speed: Using the base model directly allows us to deploy faster without the added setup.
- Adequate Performance: In several cases, pre-trained models give accuracy that is already “good enough” for production.
- Data Privacy: If we fine-tune on sensitive data such as medical records, we face risks where information might leak or be misused.
The dilemma arose once more from an ethical issue: if the system decides based only on general training data, do we lose accuracy for specific groups, or do we protect privacy by not exposing local data?
We, as learners and practitioners, look into these choices with both technical and ethical perspectives. One side values precision and domain fit through fine-tuning, while the other side values simplicity, cost reduction, and safety in using models as they are. The issue is not fully settled. It depends on the project, the people, the time, and the resources we have. What we can say is that LLMs like DistilBERT allow us to begin work in sentiment analysis and related tasks with less manual effort, but they also remind us to ask what trade-offs we are willing to accept.
Problem Statement and Objectives
Sentiment classification is about looking at text and deciding if it has a positive or negative tone. It can be used on product reviews, customer feedback, or comments that people post, and the output is often placed into two groups: positive or negative. This project takes that issue as its starting point, as we try to see what kind of results we can get when we do not train a model from the beginning but instead work with models that are already trained.
The aim of this project is to build a working sentiment analyzer that uses pre-trained Large Language Models, with a focus on DistilBERT. The idea is to check how good such a system can be for basic tasks, where we save both time and system resources and still keep accuracy at a level that is useful. We are not looking to create a complex pipeline, but to set up a data-driven way to classify sentiment that is fast, repeatable, and practical.
Tools and Libraries Used
- Hugging Face Transformers: This library gives us ready pipelines with models like DistilBERT that have already been trained, so we do not need to set up manual steps for tokenization or model calls.
- pandas: This helps us store, read, and manage data in a tabular form. It lets us check the dataset and prepare it for processing.
- scikit-learn: We use it for evaluation, where we get accuracy scores, classification reports, and confusion matrices that let us compare the system output against true labels.
- matplotlib: This library is used to make plots, for example, to show the distribution of labels or the outcomes of predictions.
- TextBlob: We include it as an additional check because it is based on a lexical method and lets us compare results with another approach.
These tools fit the need for quick prototyping because they are easy to install, well documented, and often used in coursework and research. They help us go from dataset to results without heavy manual coding.
Data Collection and Preparation
The dataset is stored in an Excel file with columns for ID, text, and label. Each text has a label that says if it is Positive or Negative. Since the file is already in good shape, we do not make heavy changes. We load it with pandas and check the first few rows to make sure the data looks correct.
data
| ID | Text | Label |
| 1 | I love learning about AI and Machine Learning. | Positive |
| 2 | This is the worst movie I have ever watched. | Negative |
| 3 | Python is a very useful programming language. | Positive |
| 4 | I am not happy with the customer service. | Negative |
| 5 | The weather is nice and sunny today. | Positive |
In some projects, there may be a debate between heavy preprocessing and minimal preprocessing. A data-driven approach may say that cleaning and tokenizing are required for accuracy, while a more practical perspective may argue that using the pre-trained model directly is enough if the dataset is already structured. For this work, we keep the steps simple and focus on inference.
Applying Pre-Trained LLM for Sentiment Prediction
We set up the Hugging Face sentiment analysis pipeline, which by default loads DistilBERT trained for sentiment tasks. The pipeline makes predictions for each text in the dataset and gives a label of positive or negative.
We then attach these predicted labels back to the dataset and compare them with the given labels. For evaluation, we use accuracy, classification reports, and confusion matrices from scikit-learn. These numbers show us where the model is correct, where it is wrong, and how balanced the results are across both sentiment classes.
A further point of reflection comes in how we see the issue of fine-tuning. On one side, fine-tuning may give better results, but it also takes time, compute, and data that may not be easy to get. On the other side, using the model as it is may be fast and still good enough for use cases where the cost of small errors is low. Both positions have weight, and the choice may depend on the case at hand.
Evaluating Model Performance
We used several metrics to check how well the sentiment classification model worked. Accuracy gave us the share of correct predictions out of all cases, which helped us see the general correctness of the system. The classification report gave more detailed numbers such as precision, recall, F1-score, and support for each class, which helped us check how the system behaved for positive and negative texts separately. The confusion matrix gave us the counts of true positives, true negatives, false positives, and false negatives, which helped us see where the model got the result right and where it did not.
When we read the results, we saw that the accuracy and F1-score were both high. This told us that the pre-trained model was able to classify sentiment in the dataset with good correctness. The confusion matrix showed that there were only a few wrong predictions, which suggested that the model fit well for this type of issue. From this point, we can say that using pre-trained models without fine-tuning can still give useful results for basic classification work, though we may still ask if that would hold true on harder datasets.
Visualization of Results
We made a confusion matrix plot using matplotlib. The plot gave a visual display of the counts of correct and incorrect predictions with colors that made it easier to see patterns. We could also add bar charts to show precision, recall, or F1-scores for each class, which would give a clear way to compare performance across labels.
These visual outputs helped us check the model in a way that was faster to read than raw numbers. For example, a confusion matrix can make it simple to see if the system tends to put negative cases into the positive class or the other way around. This type of check can help us decide where the system may need more work.
Deployment and Future Improvements
We saved the predictions, together with the inputs and true labels, into an Excel file named llm_results.xlsx. This step made the results easy to use again, either for reporting or for linking into another system.
If we want to turn the work into a live tool, we can use frameworks like Streamlit or Flask. With such tools, a person can type a new text and get the model output in real time. This can be useful for small company use cases where quick checks of reviews or comments are needed.
There are also points for future work. Fine-tuning the pre-trained model with data from a special domain may improve accuracy on domain-specific cases, but it takes time, data, and compute. Larger models such as BERT-large or RoBERTa may also give higher accuracy, but they need more resources. Expanding the dataset with more diverse text can improve generalization. Each of these paths has trade-offs in cost, time, and performance.
This project showed the process of applying pre-trained Large Language Models to sentiment analysis. We moved from loading a dataset and checking its state, to using a model for predictions, to evaluating results with both numbers and plots. The main point is not only that the system gave good results, but also that we had a chance to think about the balance between speed, cost, and correctness.
We may ask: Should we always fine-tune for the highest accuracy, or is it enough to use pre-trained models as they are for simple tasks? The answer may change with the case, the resources, and the stakes of wrong predictions. By working on such projects, we get to think about these questions, which may guide us in later work.
Downloadable Sourcecode:
Next Step – Explore Services with Craze Neurons
When we look at the path to growing our skills, career, or business, we find that it is not only about time or effort but about the ways in which we use guidance, tools, and experience. At Craze Neurons, we offer a set of services that can act as a lens into knowledge, performance, and opportunity. Through these offerings, we can see the depth of learning and the perspective that comes from practical engagement.
- Upskilling Training – We provide hands-on training in Data Science, Python, AI, and related fields. This is a way for us to look at learning from both practical and conceptual perspectives.
👉 Click here to know more: https://wa.me/918368195998?text=I%20want%20to%20Upskill%20with%20Craze%20Neurons - ATS-Friendly Resume – Our team can craft resumes that are optimized for Applicant Tracking Systems (ATS), highlighting skills, experiences, and achievements. This service is available at ₹599, providing a tangible way for us to make first impressions count.
👉 Click here to know more: https://wa.me/918368195998?text=I%20want%20an%20ATS-Friendly%20Resume%20from%20Craze%20Neurons - Web Development – We build responsive, SEO-friendly websites that can be a framework for growth. It is a way for us to put ideas into structure, visibility, and functionality.
👉 Click here to know more: https://wa.me/918368195998?text=I%20want%20a%20Website%20from%20Craze%20Neurons - Android Projects – These are real-time projects designed with the latest tech stack, allowing us to learn by doing. Guided mentorship gives us a chance to look at development from a practical lens and to understand the why behind each decision.
👉 Click here to know more: https://wa.me/918368195998?text=I%20want%20an%20Android%20Project%20with%20Guidance - Digital Marketing – We provide campaigns in SEO, social media, content, and email marketing, which can be used to see our brand’s reach and engagement from a deeper perspective.
👉 Click here to know more: https://wa.me/918368195998?text=I%20want%20Digital%20Marketing%20Support - Research Writing – We deliver plagiarism-free thesis, reports, and papers, which can help us explore knowledge, present ideas, and communicate insight with clarity.
👉 Click here to know more: https://wa.me/918368195998?text=I%20want%20Research%20Writing%20Support
In all these services, we can see that learning, building, promoting, or publishing is not just a task but a process of discovery. It is a way for us to understand, measure, and reflect on what is possible when guidance meets effort.
❓ Frequently Asked Questions (FAQs) – Craze Neurons Services
1. What is included in the Upskilling Training?
We provide hands-on training in Data Science, Python, AI, and allied fields. This allows us to work with concepts and projects, see practical applications, and explore the deeper understanding of each topic.
2. How does the ATS-Friendly Resume service work?
Our team crafts ATS-optimized resumes that highlight skills, experience, and achievements. This is a service priced at ₹599 and acts as a lens to make the first impression clear, measurable, and effective.
3. What kind of websites can Craze Neurons build?
We build responsive and SEO-friendly websites for businesses, personal portfolios, and e-commerce platforms. This enables us to translate ideas into structure, visibility, and functional design.
4. What are the Android Projects about?
We offer real-time Android projects with guided mentorship. This gives us an opportunity to learn by doing, understand development from multiple angles, and apply knowledge in a controlled, real-world context.
5. What does Digital Marketing service include?
Our service covers SEO, social media campaigns, content marketing, and email strategy, allowing us to look at brand growth quantitatively and qualitatively, understanding what works and why.
6. What type of Research Writing do you provide?
We provide plagiarism-free academic and professional content, including thesis, reports, and papers. This allows us to express ideas, support arguments, and explore knowledge with depth and precision.
7. How can I get started with Craze Neurons services?
We can begin by clicking the WhatsApp link for the service we are interested in. This lets us communicate directly with the team and explore the steps together.
8. Can I use multiple services together?
Yes, we can combine training, resume, web, Android, digital marketing, and research services. This allows us to see synergies, plan strategically, and use resources effectively.
9. Is the training suitable for beginners?
Absolutely. The courses are designed for learners at all levels. They allow us to progress step by step, integrate projects, and build confidence alongside skills.
10. How long does it take to complete a service or course?
Duration depends on the service. Training programs vary by course length. Projects may take a few weeks, while resume, website, or research work can often be completed within a few days. This helps us plan, manage, and achieve outcomes efficiently.
Stay Connected with Us
🌐 Website: www.crazeneurons.com
📢 Telegram: https://t.me/cenjob
📸 Instagram: https://www.instagram.com/crazeneurons
💼 LinkedIn: https://www.linkedin.com/company/crazeneurons
▶️ YouTube:https://www.youtube.com/@CrazeNeurons
📲 WhatsApp: +91 83681 95998