Reliable Strategies to Clean and Transform Incomplete Datasets
1. Introduction
In real-world data analysis, missing values are a common occurrence. Data may become incomplete due to various reasons such as data collection errors, system failures, user omissions, or data corruption. If not handled properly, missing values can reduce model accuracy and introduce bias, leading to unreliable results.
Managing missing data is a crucial step in data preprocessing. Appropriate handling techniques help transform incomplete datasets into reliable inputs for machine learning models through effective data cleaning and transformation.
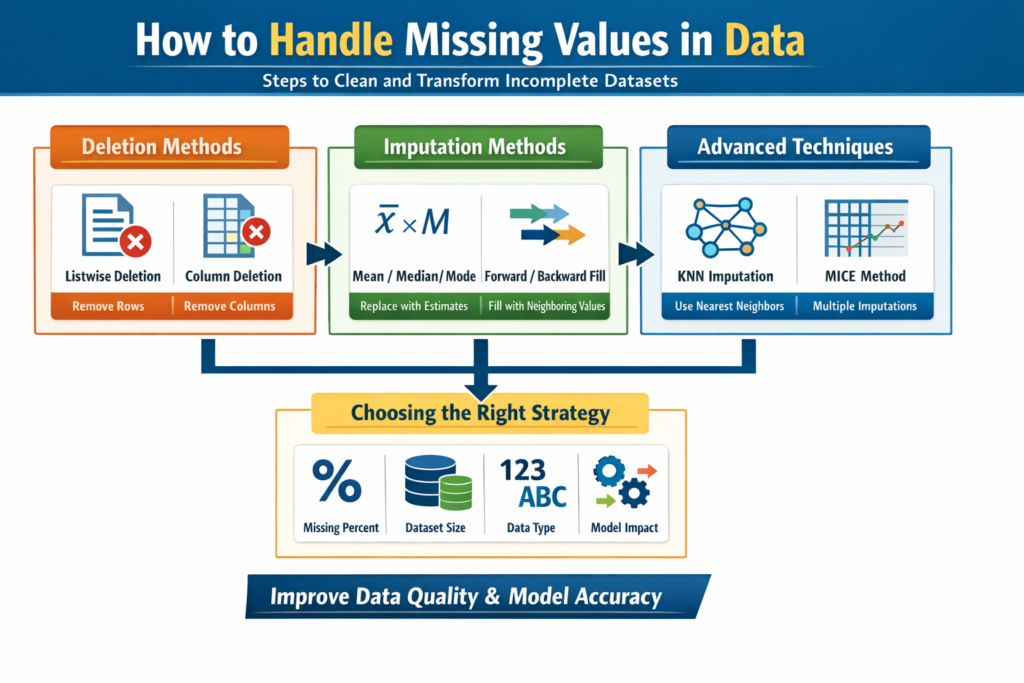
The above image presents a structured workflow for handling missing values in data, a critical step in data preprocessing for machine learning and analytics. It categorizes the process into four major stages: deletion methods, imputation techniques, advanced algorithms, and strategy selection.
The first section highlights deletion methods, including listwise deletion (removing rows with missing values) and column deletion (dropping features with excessive missing data). These approaches are simple and effective when the proportion of missing data is minimal.
The second section focuses on imputation methods, where missing values are replaced with estimated values. Common techniques such as mean, median, and mode imputation are shown, along with forward and backward fill methods typically used in time-series datasets.
Next, the infographic introduces advanced techniques like K-Nearest Neighbors (KNN) imputation and Multiple Imputation by Chained Equations (MICE). These methods leverage data patterns and relationships to provide more accurate and reliable estimations, especially in complex datasets.
The final section emphasizes choosing the right strategy, based on factors such as the percentage of missing data, dataset size, data type, and its impact on model performance. This step is crucial to ensure optimal data quality and prevent bias in analysis.
Overall, the infographic visually simplifies the decision-making process for handling missing data, helping data scientists and analysts improve dataset reliability and enhance machine learning model accuracy.
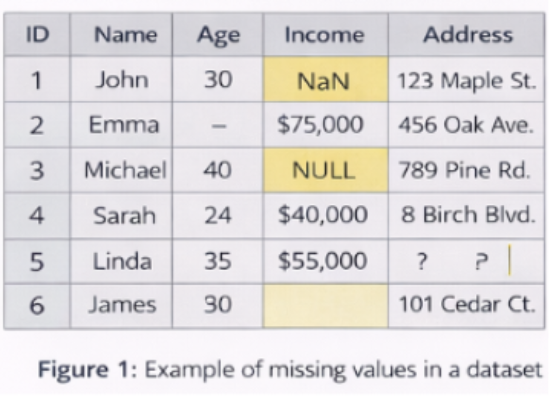
2. What Are Missing Values?
Missing values occur when no data is stored for a particular variable in an observation. They can appear in several forms:
- Empty cells
- NULL values
- NaN (Not a Number)
- Special symbols (e.g., “?”, “–”)
Understanding the reason behind missing data is essential, as different causes require different handling approaches.
Missingness in Data
3. Types of Missingness
Understanding the nature of missing data helps in selecting the most appropriate strategy.
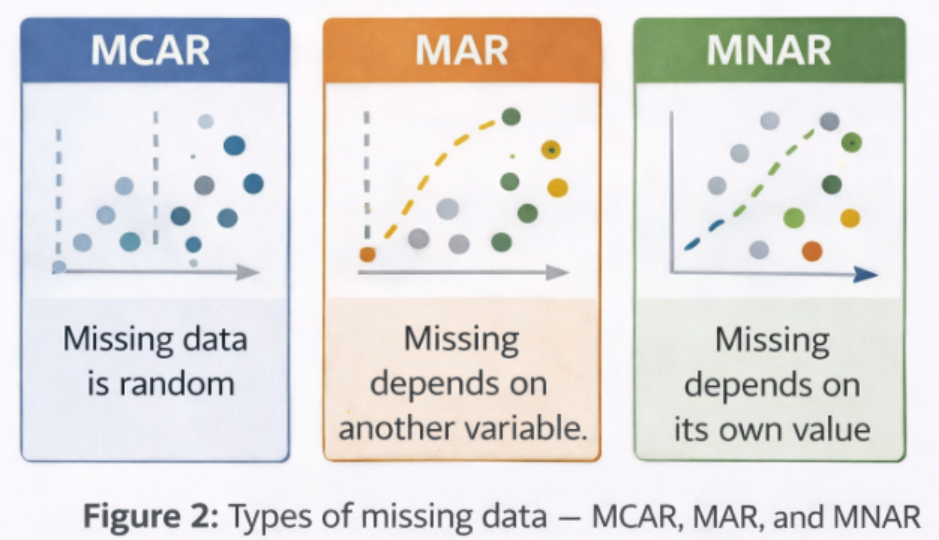
3.1 Missing Completely at Random (MCAR)
- Missing data occurs randomly and is independent of any variables.
- Example: A sensor fails randomly during data collection.
Characteristics:
- No identifiable pattern
- Does not introduce bias
- Data can be safely removed or imputed
3.2 Missing at Random (MAR)
- Missingness depends on observed variables but not on the missing value itself.
- Example: Younger individuals are less likely to report income.
Characteristics:
- Related to other variables
- Requires careful imputation
- Can introduce bias if not handled properly
3.3 Missing Not at Random (MNAR)
- Missingness depends on the actual missing value.
- Example: High-income individuals choosing not to disclose income.
Characteristics:
- High risk of bias
- Difficult to handle
- Requires domain expertise
4. Methods to Handle Missing Values
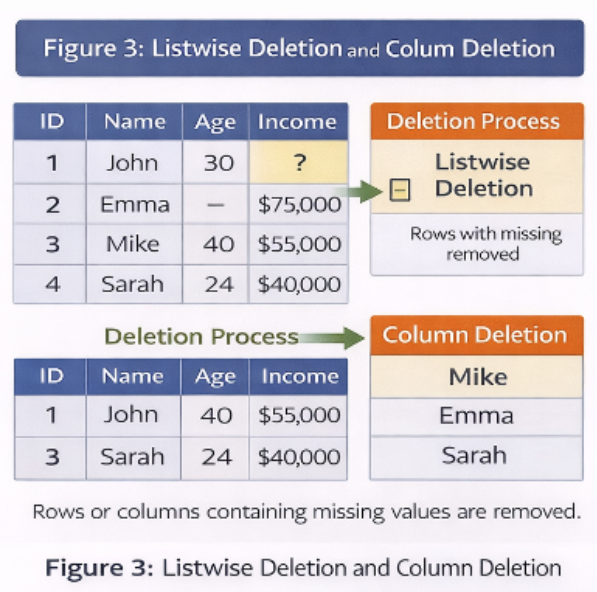
4.1 Deletion Methods
Removal of data points or features containing missing values.
a) Listwise Deletion
- Removes entire rows with missing values
Advantages:
- Simple to implement
- Effective for small amounts of missing data
Disadvantages:
- Loss of data
- Reduced dataset size
b) Column Deletion
- Removes entire columns with excessive missing values
Used when:
- Feature is not important
- Large proportion of missing data
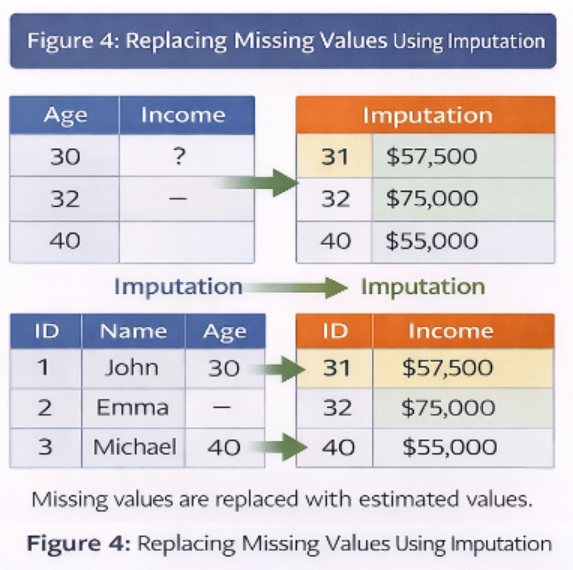
4.2 Imputation Methods
Replacing missing values with estimated values.
a) Mean / Median / Mode Imputation
- Mean → Numerical data
- Median → Skewed data
- Mode → Categorical data
Advantages:
- Easy to implement
- Fast computation
Limitations:
- Reduces variability
- May introduce bias
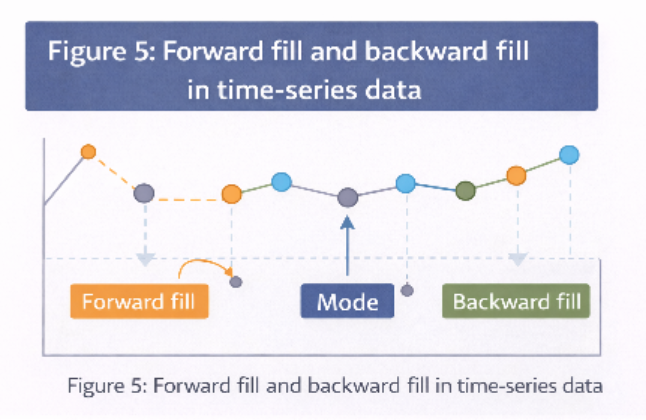
b) Forward Fill / Backward Fill
- Common in time-series data
- Forward fill → Uses previous value
- Backward fill → Uses next value
5. Advanced Techniques for Missing Values
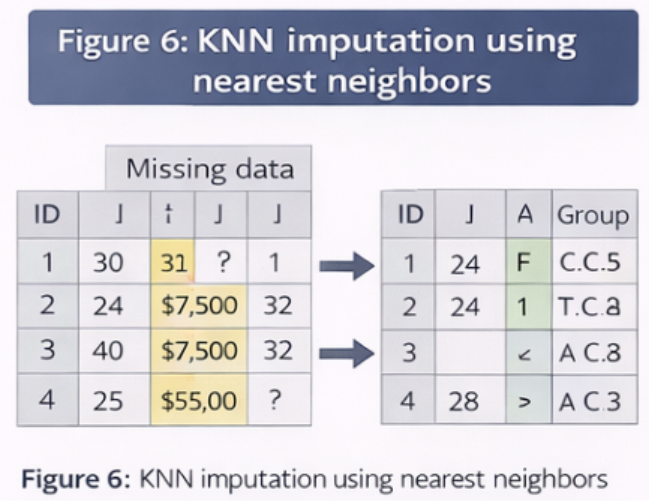
5.1 K-Nearest Neighbors (KNN) Imputation
- Uses similar data points to estimate missing values
Working:
- Identifies nearest neighbors
- Uses their values to fill missing data
Advantages:
- More accurate than basic methods
- Captures data patterns
Limitations:
- Computationally expensive
- Not efficient for large datasets
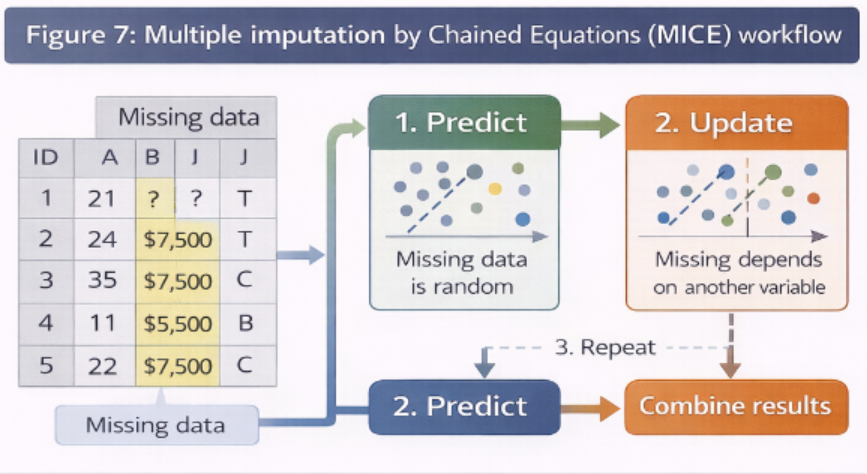
5.2 Multiple Imputation by Chained Equations (MICE)
- Uses multiple regression models to estimate missing values
Process:
- Predict missing values
- Iteratively update dataset
- Combine results
Advantages:
- High accuracy
- Preserves relationships in data
- Reduces bias
Limitations:
- Complex implementation
- High computational cost
6. Choosing the Right Strategy
Selection depends on:
- Percentage of missing data
- Dataset size
- Data type (numerical/categorical)
- Impact on model performance
General Guidelines:
- Small missing data → Deletion or simple imputation
- Moderate missing data → Statistical imputation
- Complex datasets → Advanced methods (KNN, MICE)
7. Impact of Missing Values on Machine Learning
Unmanaged missing data can:
- Reduce predictive accuracy
- Introduce bias
- Cause algorithm failures
- Distort statistical analysis
Proper handling improves model reliability and performance.
8. Conclusion
Handling missing values is a fundamental step in data preprocessing. Understanding the types of missingness—MCAR, MAR, and MNAR—enables the selection of appropriate techniques. While basic methods like deletion and mean imputation are useful, advanced approaches such as KNN and MICE provide better accuracy for complex datasets. Effective management of missing data ensures reliable analysis and enhances machine learning model performance.
For deeper context and practical extensions across AI, data science, automation, Python, careers, and industry trends, explore these related articles:
Your Next Step: Turn Learning Into Real Outcomes
Learning creates understanding. Progress comes from applying it with the right guidance. Use the table below to identify your immediate goal, understand what support fits best, and take a clear next step with Craze Neurons.
| What You Need Right Now! | What This Service Helps You Achieve | Starting At | Next Step |
| Upskilling Training | Real-world capability in Data Science, Python, AI, and related fields through hands-on training, live projects, mentorship, and strong conceptual grounding. | ₹2000 | 👉 Start upskilling |
| ATS-Friendly Resume | An ATS-optimized resume that reaches recruiters, built using skill-focused structuring and precise keyword optimization aligned with hiring systems. | ₹599 | 👉 Get an ATS-ready resume |
| Web Development | A responsive, SEO-friendly website designed for visibility and growth, using performance-driven design, clean structure, and search readiness. | ₹5000 | 👉Get Web site support |
| Android Projects | Practical Android development experience gained through real-time projects, guided mentorship, and clear explanations behind technical decisions. | ₹10000 | 👉 Get Android support |
| Digital Marketing | Increased brand visibility and engagement achieved through data-driven SEO, content strategy, social media, and email marketing campaigns. | ₹5000 | 👉 Get digital marketing support |
| Research Writing | Clear, plagiarism-free academic and technical writing delivered through structured, original research with academic integrity. | ₹5000 | 👉 Get research writing support |
❓ Frequently Asked Questions (FAQs) – Craze Neurons Services
0. Not sure which option fits your situation?
A short discussion is often enough to identify the most effective path. We help you clarify scope, effort, and outcomes before you commit.
👉 Talk to Craze Neurons on WhatsApp
1. What is included in the Upskilling Training?
We provide hands-on training in Data Science, Python, AI, and allied fields. This allows us to work with concepts and projects, see practical applications, and explore the deeper understanding of each topic.
2. How does the ATS-Friendly Resume service work?
Our team crafts ATS-optimized resumes that highlight skills, experience, and achievements. This is a service priced at ₹599 and acts as a lens to make the first impression clear, measurable, and effective.
3. What kind of websites can Craze Neurons build?
We build responsive and SEO-friendly websites for businesses, personal portfolios, and e-commerce platforms. This enables us to translate ideas into structure, visibility, and functional design.
4. What are the Android Projects about?
We offer real-time Android projects with guided mentorship. This gives us an opportunity to learn by doing, understand development from multiple angles, and apply knowledge in a controlled, real-world context.
5. What does Digital Marketing service include?
Our service covers SEO, social media campaigns, content marketing, and email strategy, allowing us to look at brand growth quantitatively and qualitatively, understanding what works and why.
6. What type of Research Writing do you provide?
We provide plagiarism-free academic and professional content, including thesis, reports, and papers. This allows us to express ideas, support arguments, and explore knowledge with depth and precision.
7. How can I get started with Craze Neurons services?
We can begin by clicking the WhatsApp link for the service we are interested in. This lets us communicate directly with the team and explore the steps together.
8. Can I use multiple services together?
Yes, we can combine training, resume, web, Android, digital marketing, and research services. This allows us to see synergies, plan strategically, and use resources effectively.
9. Is the training suitable for beginners?
Absolutely. The courses are designed for learners at all levels. They allow us to progress step by step, integrate projects, and build confidence alongside skills.
10. How long does it take to complete a service or course?
Duration depends on the service. Training programs vary by course length. Projects may take a few weeks, while resume, website, or research work can often be completed within a few days. This helps us plan, manage, and achieve outcomes efficiently.
Stay Connected with Us
🌐 Website 📢 Telegram 📸 Instagram 💼 LinkedIn ▶️ YouTube 📲 WhatsApp: +91 83681 95998